Machine Learning - Logistic regression experiments
Learning Logistic Regression with scikit-learn and pandas
1. Get the data, define the problem
The sinking of the Titanic is one of the most infamous shipwrecks in history.On April 15, 1912, during its first voyage, the Titanic sank after hitting an iceberg, killing 1,502 of the 2,224 passengers and crew. One of the reasons for the loss of life was that there were not enough lifeboats for the passengers and crew. While there were factors that contributed to the luck of surviving, some people were more likely to survive than others, such as women, children and the upper class.
The Titanic dataset is divided into two parts:
Training dataset-contains feature information and labels for survival and non-survival, train.csv
Test dataset - contains only feature information, test.csv
The dataset can be downloaded from kaggle in csv format.
You can also download it from my csdn resources at Click to download
We are going to use the tools of machine learning to predict which passengers are more likely to survive the disaster.
In this lesson’s challenge, we are going to use a logistic regression algorithm to complete an analysis of which people are more likely to survive.
In scikit-learn, logistic regression is implemented through the linear_model.LogisticRegression class.
|
|
Reference: https://www.cnblogs.com/wjq-Law/p/9779657.html
|
|
2. View Data

Data columns (total 12 columns):
| PassengerId | 891 non-null int64 |
| Pclass | 891 non-null int64 |
| Name | 891 non-null object |
| Sex | 891 non-null object |
| Age | 714 non-null float64 |
| SibSp | 891 non-null int64 |
| Parch | 891 non-null int64 |
| Ticket | 891 non-null object |
| Fare | 891 non-null float64 |
| Cabin | 204 non-null object |
| Embarked | 889 non-null object |
It can be seen that the training set contains a total of 891 samples with 12 features each, of which Age, Cabin and Embarked have missing values. In particular, the Carbin feature has values for only 204 samples.
Similarly: observe the missing values in the test set.
Additional functions to view the data:
|
|
3. Handling of missing values
Age features are very important (ladies and children are usually preferred when fleeing for their lives), so we need to fill them.
The methods of filling missing values are: fixed value filling, mean/median filling, adjacent value filling, and model prediction filling.
Here we use mean fill. fillna() function.

Cabin has more missing values, and we directly discard them to avoid introducing larger noise. (Delete a feature, column) with the drop() function.

Embarked features have only 2 samples with missing values in the training set, so the samples with missing values can be removed directly. (Delete a sample, line)

Similarly, the missing values of the test set are processed.
4. Feature Processing
There are still some problems with the current data, such as the Name feature is text-based, which is not conducive to subsequent processing, so we temporarily discard it when training the model, and the Ticket feature is messy, so we also ignore it temporarily.

Pclass features, Sex features, and Embarked features are all category types, which generally need to be one-hot encoded.

Age features, SibSp features, Parch features and Fare features are numerical and have a wide range of values, so they are generally normalized or normalized first.
The standardization uses the fit() function and fit_transform() function in the preprocessing.StandardScaler class library.
fit() is used to calculate the mean and variance of the training data, which are later used to transform the training data.
fit_transform() not only calculates the mean and variance of the training data, but also transforms the training data based on the calculated mean and variance, thus converting the data into a standard orthogonal distribution.




5. Model Training
(1) Import the required classification algorithm class library.
|
|
The parameters of the logistic regression function are as follows:
|
|
(2) Extract the feature values and labels in the training set separately.
(3) Divide the training set and the validation set.
train_test_split() Function
(4) Training model.
fit() Function
(5) Verify on the validation set and evaluate the performance.





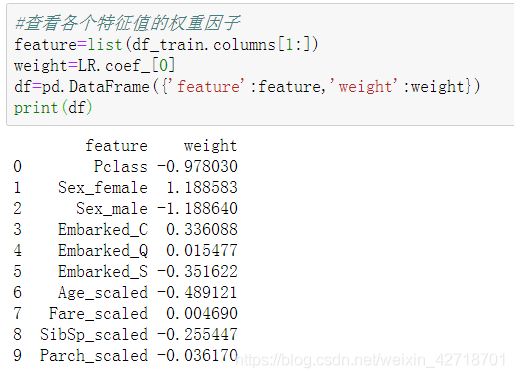
The model has been trained and is performing well enough to be used for prediction.
6. Complete python code
|
|