1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
|
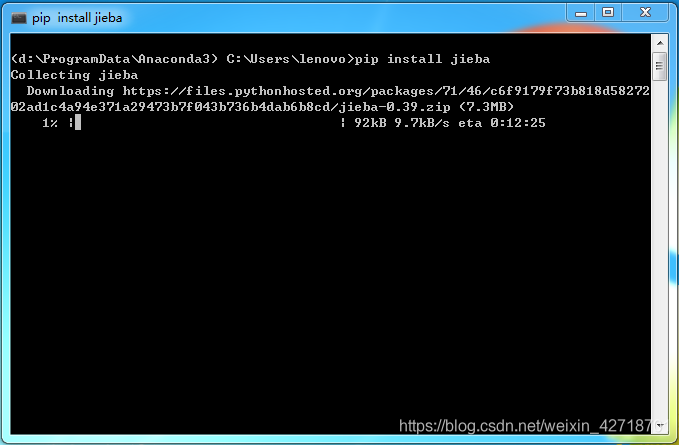
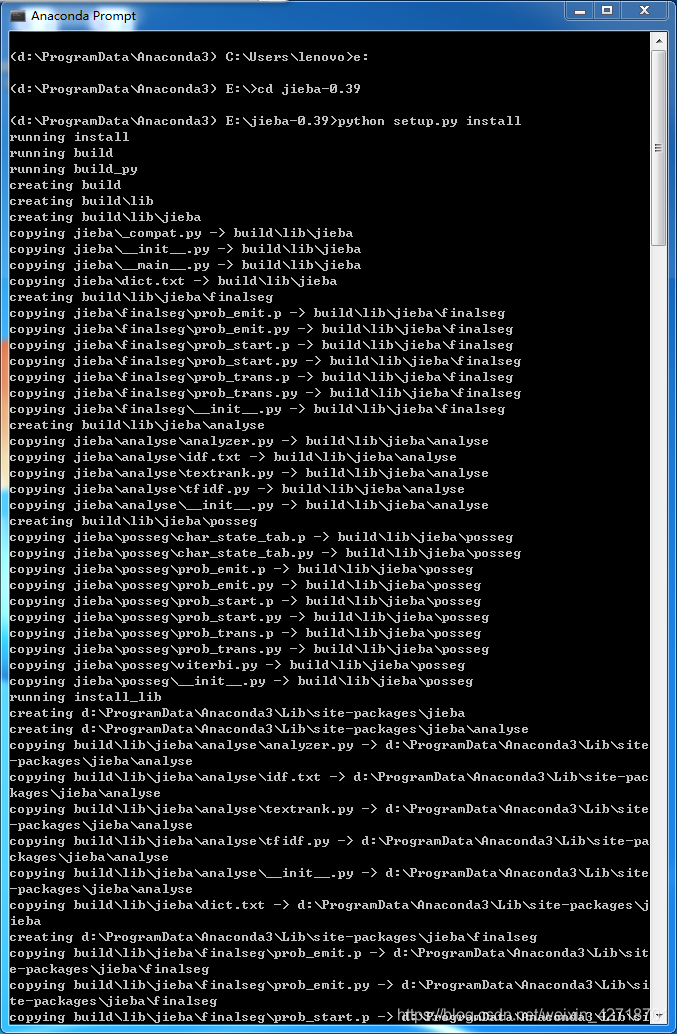
import jieba #需要先安装结巴类库,再引入,否则报错
seg_list=jieba.cut("西京网讯:10月31日晚,“庆祝中华人民共和国成立70周年暨西京学院建校25周年教职工竹竿舞比赛”举行。",cut_all=True)
print("Full Mode全切分模式:","/".join(seg_list))
seg_list=jieba.cut("教师五分会的《欢乐西京团》与教师二分会的《跳起来》伴随着活泼的音乐和轻盈的舞蹈,把“欢乐”表现的淋淋尽致。")
print("搜索引擎分词模式:","/".join(seg_list))
seg_list=jieba.cut("2019年底部队友谊篮球赛结束",cut_all=False)
print("默认切分模式:","/".join(seg_list))
seg_list=jieba.cut("西京网讯:10月31日晚,“庆祝中华人民共和国成立70周年暨西京学院建校25周年教职工竹竿舞比赛”举行。",cut_all=False)
print("Full Mode全切分模式:","/".join(seg_list))
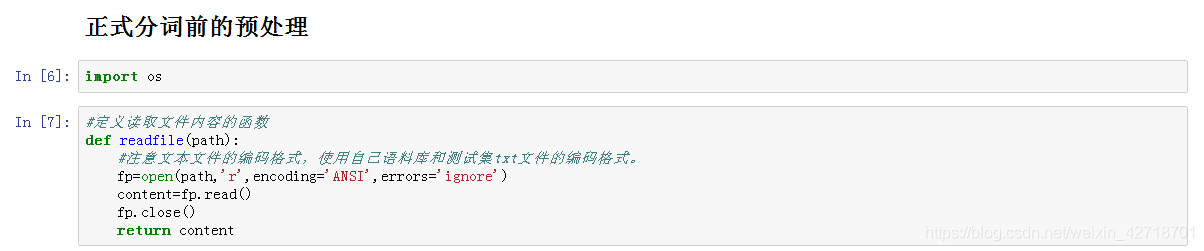
import os
#定义读取文件内容的函数
def readfile(path):
#注意文本文件的编码格式,使用自己语料库和测试集txt文件的编码格式。
fp=open(path,'r',encoding='ANSI',errors='ignore')
content=fp.read()
fp.close()
return content
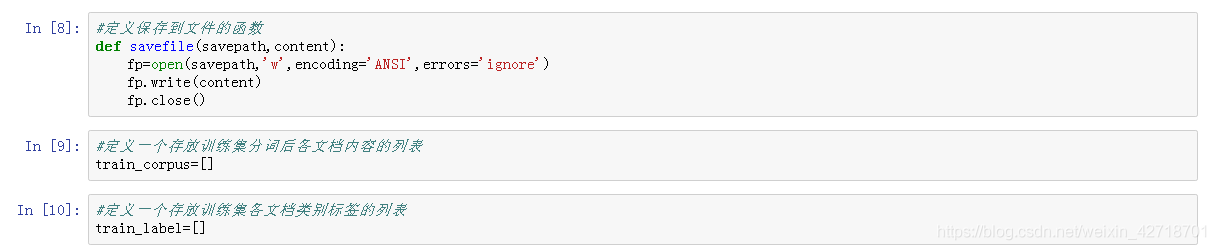
#定义保存到文件的函数
def savefile(savepath,content):
fp=open(savepath,'w',encoding='ANSI',errors='ignore')
fp.write(content)
fp.close()
#定义一个存放训练集分词后各文档内容的列表
train_corpus=[]
#定义一个存放训练集各文档类别标签的列表
train_label=[]
#未分词的训练集语料库路径,替换为自己电脑保存的路径。train_corpus文件夹。
corpus_path="E:/program/train_corpus/"
#训练集分词以后存放路径,自己提前建立好名字为seg_train_corpus的空文件夹
save_path="E:/program/seg_train_corpus/"
#获取未分词的语料库下所有子目录列表
cate_list=os.listdir(corpus_path)
print("努力分词中,请稍等.........")
#获取每个子目录下的所有文件
for mydir in cate_list:
class_path=corpus_path+mydir+'/' #语料集中的某个子目录路径
seg_dir=save_path+mydir+'/' #分类后的子目录路径
file_list=os.listdir(class_path) #获取具体的文件名称列表
for file_path in file_list:
fullname=class_path + file_path
content=readfile(fullname).strip() #str.strip()就是把字符串(str)的头和尾的空格,以及位于头尾的\n \t之类给删掉
content=content.replace("\r\n","").strip() #删除换行和多余的空格
content_seg=jieba.cut(content)
savefile(seg_dir+file_path," ".join(content_seg))
train_label.append(mydir)
print("训练集语料库文本分词结束!")
oldpath=r"e:/program/seg_train_corpus/"
newpath=r"e:/program/seg_val_corpus/"
import random #随机排序文件
import shutil
#从训练集中随机取出20%的文件,保存为验证集。
catelist=os.listdir(oldpath)
for eachlist in catelist:
fullpath=oldpath+eachlist
newvalpath=newpath+eachlist+"/"
isExists=os.path.exists(newvalpath) #判断路径是否存在,若存在,报错。不存在,创建。
if isExists==True:
print(newvalpath+"目录已存在,将不再保存新的文件!请确认是否已划分好。")
else:
os.makedirs(newvalpath,exist_ok=True)
filename=os.listdir(fullpath)
filenumber=len(filename)
random.shuffle(filename) #将文件随机排序
splitfile=int(filenumber*0.2)
for i in range(splitfile): #将随机抽取出的20%文件保存到验证集目录下。
src=fullpath+"/"+filename[i]
shutil.move(src,newvalpath)
print("目录"+newvalpath+"创建成功!")
print("训练集和验证集划分完毕")
newvalpath
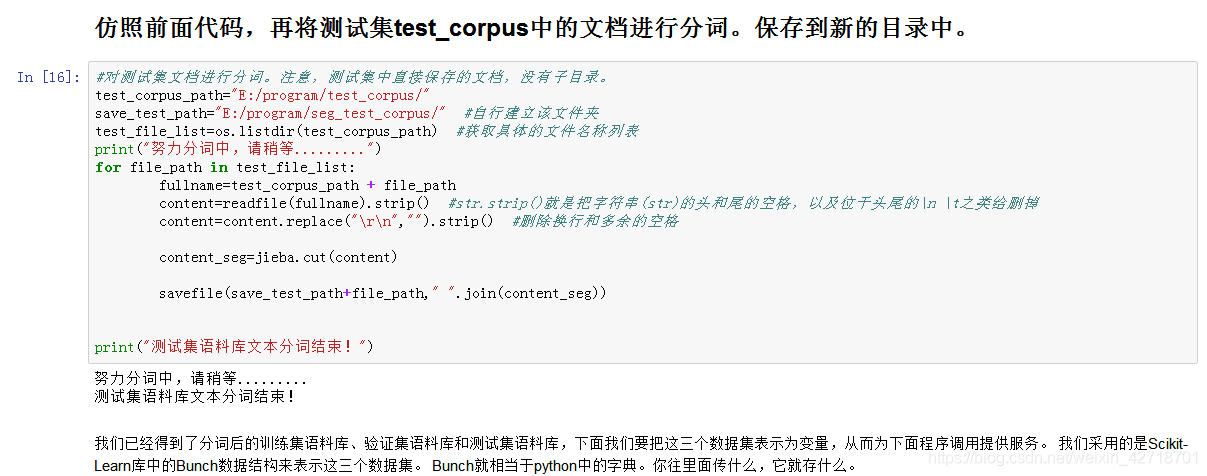
#对测试集文档进行分词。注意,测试集中直接保存的文档,没有子目录。
test_corpus_path="E:/program/test_corpus/"
save_test_path="E:/program/seg_test_corpus/" #自行建立该文件夹
test_file_list=os.listdir(test_corpus_path) #获取具体的文件名称列表
print("努力分词中,请稍等.........")
for file_path in test_file_list:
fullname=test_corpus_path + file_path
content=readfile(fullname).strip() #str.strip()就是把字符串(str)的头和尾的空格,以及位于头尾的\n \t之类给删掉
content=content.replace("\r\n","").strip() #删除换行和多余的空格
content_seg=jieba.cut(content)
savefile(save_test_path+file_path," ".join(content_seg))
print("测试集语料库文本分词结束!")
from sklearn.datasets.base import Bunch
bunch = Bunch(target_name=[],label=[],filenames=[],contents=[])
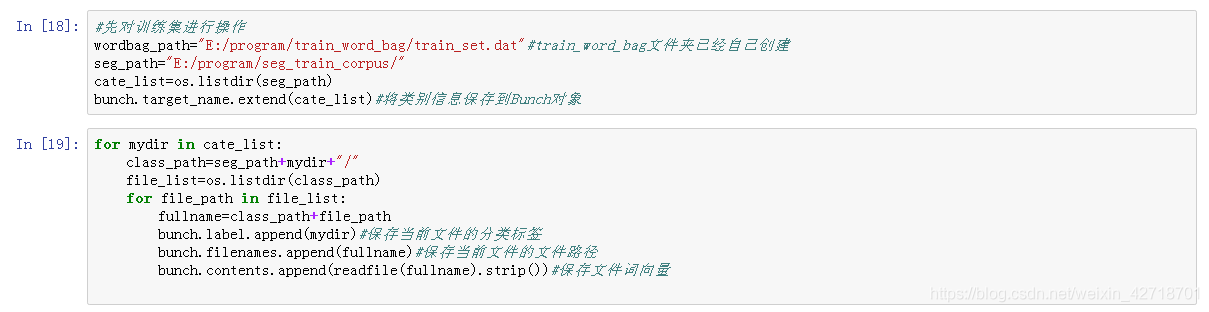
#先对训练集进行操作
wordbag_path="E:/program/train_word_bag/train_set.dat"#train_word_bag文件夹已经自己创建
seg_path="E:/program/seg_train_corpus/"
cate_list=os.listdir(seg_path)
bunch.target_name.extend(cate_list)#将类别信息保存到Bunch对象
for mydir in cate_list:
class_path=seg_path+mydir+"/"
file_list=os.listdir(class_path)
for file_path in file_list:
fullname=class_path+file_path
bunch.label.append(mydir)#保存当前文件的分类标签
bunch.filenames.append(fullname)#保存当前文件的文件路径
bunch.contents.append(readfile(fullname).strip())#保存文件词向量
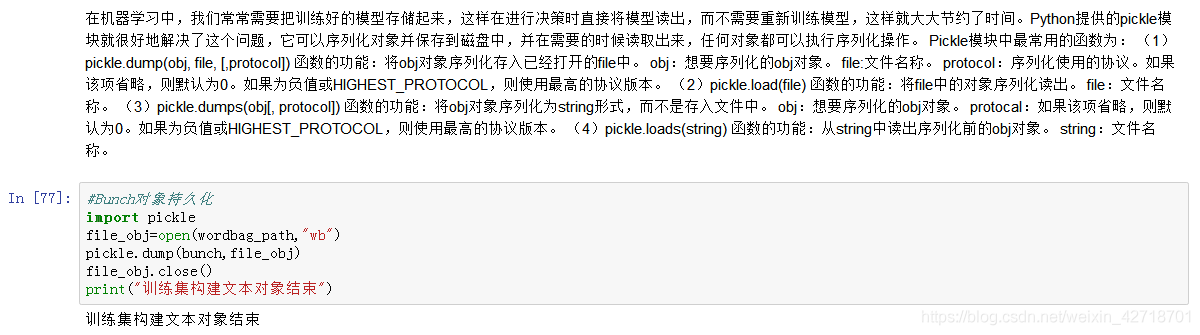
#Bunch对象持久化
import pickle
file_obj=open(wordbag_path,"wb")
pickle.dump(bunch,file_obj)
file_obj.close()
print("训练集构建文本对象结束")
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer#TF-IDF向量转换类
from sklearn.feature_extraction.text import TfidfVectorizer#TF-IDF向量生成类
def readbunchobj(path):
file_obj=open(path,"rb")
bunch=pickle.load(file_obj)
file_obj.close()
return bunch
def writebunchobj(path,bunchobj):
file_obj=open(path,"wb")
pickle.dump(bunchobj,file_obj)
file_obj.close()
def readfile(path):
fp = open(path,"r",encoding='ANSI',errors='ignore')
content = fp.read()
fp.close()
return content
path="E:/program/train_word_bag/train_set.dat"
bunch=readbunchobj(path)
#停用词
stopword_path="E:/program/hlt_stop_words.txt"
stpwrdlst=readfile(stopword_path).splitlines()
#构建TF-IDF词向量空间对象
tfidfspace=Bunch(target_name=bunch.target_name,label=bunch.label,filenames=bunch.filenames,tdm=[],vocabulary={})
#使用TfidVectorizer初始化向量空间模型
vectorizer=TfidfVectorizer(stop_words=stpwrdlst,sublinear_tf=True,max_df=0.5)
#transformer=TfidfTransformer()#该类会统计每个词语的TF-IDF权值
#文本转为词频矩阵,单独保存字典文件
tfidfspace.tdm=vectorizer.fit_transform(bunch.contents)
tfidfspace.vocabulary=vectorizer.vocabulary_
#创建词袋的持久化
space_path="E:/program/train_word_bag/tfidfspace.dat"
writebunchobj(space_path,tfidfspace)
tfidfspace.tdm.shape
bunch = Bunch(target_name=[],label=[],filenames=[],contents=[])
wordbag_path="E:/program/val_word_bag/val_set.dat"#train_word_bag文件夹已经自己创建
seg_path="E:/program/seg_val_corpus/"
cate_list=os.listdir(seg_path)
bunch.target_name.extend(cate_list)#将类别信息保存到Bunch对象
for mydir in cate_list:
class_path=seg_path+mydir+"/"
file_list=os.listdir(class_path)
for file_path in file_list:
fullname=class_path+file_path
bunch.label.append(mydir)#保存当前文件的分类标签
bunch.filenames.append(fullname)#保存当前文件的文件路径
bunch.contents.append(readfile(fullname).strip())#保存文件词向量
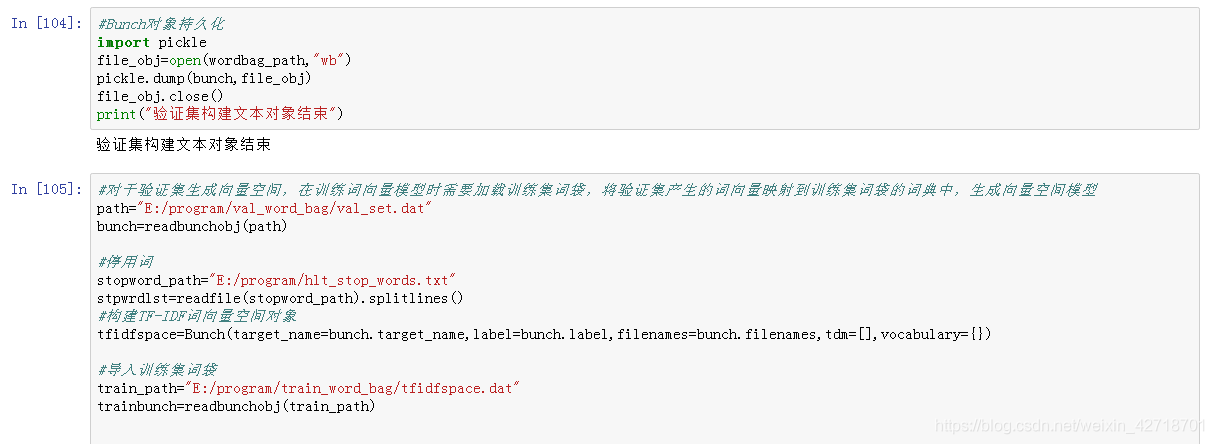
#Bunch对象持久化
import pickle
file_obj=open(wordbag_path,"wb")
pickle.dump(bunch,file_obj)
file_obj.close()
print("验证集构建文本对象结束")
#对于验证集生成向量空间,在训练词向量模型时需要加载训练集词袋,将验证集产生的词向量映射到训练集词袋的词典中,生成向量空间模型
path="E:/program/val_word_bag/val_set.dat"
bunch=readbunchobj(path)
#停用词
stopword_path="E:/program/hlt_stop_words.txt"
stpwrdlst=readfile(stopword_path).splitlines()
#构建TF-IDF词向量空间对象
tfidfspace=Bunch(target_name=bunch.target_name,label=bunch.label,filenames=bunch.filenames,tdm=[],vocabulary={})
#导入训练集词袋
train_path="E:/program/train_word_bag/tfidfspace.dat"
trainbunch=readbunchobj(train_path)
#使用TfidVectorizer初始化向量空间模型
vectorizer=TfidfVectorizer(stop_words=stpwrdlst,sublinear_tf=True,max_df=0.5,vocabulary=trainbunch.vocabulary)
#transformer=TfidfTransformer()#该类会统计每个词语的TF-IDF权值
#文本转为词频矩阵,单独保存字典文件
tfidfspace.tdm=vectorizer.fit_transform(bunch.contents)
tfidfspace.vocabulary=trainbunch.vocabulary
#创建词袋的持久化
space_path="E:/program/val_word_bag/tfidfspace.dat"
writebunchobj(space_path,tfidfspace)
type(tfidfspace.tdm)
tfidfspace.tdm.shape
bunch = Bunch(target_name=[],label=[],filenames=[],contents=[])
wordbag_path="E:/program/test_word_bag/test_set.dat"#test_word_bag文件夹已经自己创建
seg_path="E:/program/seg_test_corpus/"
file_list=os.listdir(seg_path)
for file_path in file_list:
fullname=seg_path+file_path
bunch.filenames.append(fullname)#保存当前文件的文件路径
bunch.contents.append(readfile(fullname).strip())#保存文件词向量
#Bunch对象持久化
file_obj=open(wordbag_path,"wb")
pickle.dump(bunch,file_obj)
file_obj.close()
print("测试集构建文本对象结束")
path="E:/program/test_word_bag/test_set.dat"
bunch=readbunchobj(path)
#停用词
stopword_path="E:/program/hlt_stop_words.txt"
stpwrdlst=readfile(stopword_path).splitlines()
#构建TF-IDF词向量空间对象
tfidfspace=Bunch(target_name=bunch.target_name,label=bunch.label,filenames=bunch.filenames,tdm=[],vocabulary={})
#使用TfidVectorizer初始化向量空间模型
vectorizer=TfidfVectorizer(stop_words=stpwrdlst,sublinear_tf=True,max_df=0.5)
transfoemer=TfidfTransformer()#该类会统计每个词语的TF-IDF权值
#文本转为词频矩阵,单独保存字典文件
tfidfspace.tdm=vectorizer.fit_transform(bunch.contents)
#tfidfspace.vocabulary=vectorizer.vocabulary
#创建词袋的持久化
space_path="E:/program/test_word_bag/tfidfspace.dat"
writebunchobj(space_path,tfidfspace)
from sklearn.naive_bayes import MultinomialNB# 导入多项式贝叶斯算法包
# 导入训练集向量空间
trainpath = "E:/program/train_word_bag/tfidfspace.dat"
train_set = readbunchobj(trainpath)
# 导入验证集向量空间
valpath = "E:/program/val_word_bag/tfidfspace.dat"
val_set = readbunchobj(valpath)
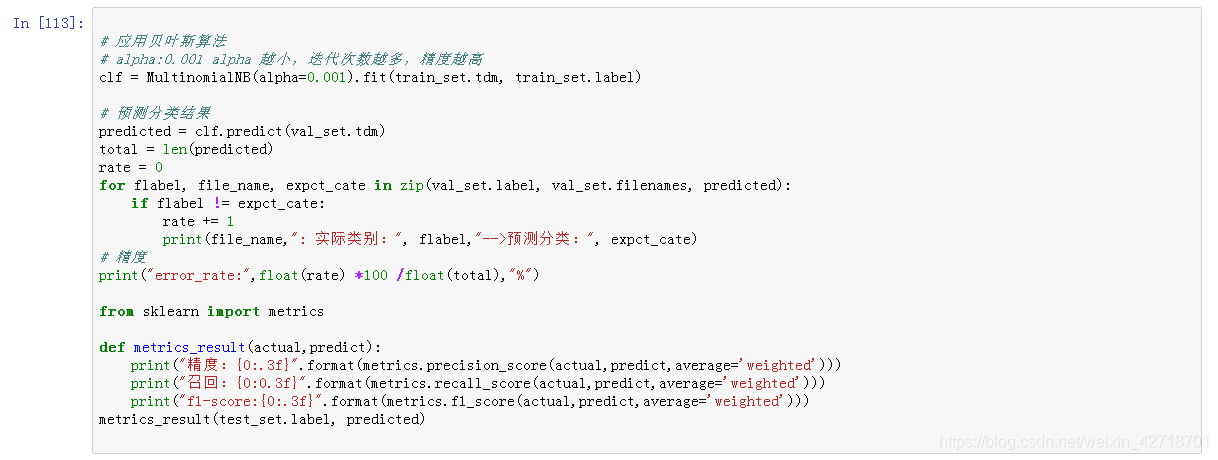
# 应用贝叶斯算法
# alpha:0.001 alpha 越小,迭代次数越多,精度越高
clf = MultinomialNB(alpha=0.001).fit(train_set.tdm, train_set.label)
# 预测分类结果
predicted = clf.predict(val_set.tdm)
total = len(predicted)
rate = 0
for flabel, file_name, expct_cate in zip(val_set.label, val_set.filenames, predicted):
if flabel != expct_cate:
rate += 1
print(file_name,": 实际类别:", flabel,"-->预测分类:", expct_cate)
# 精度
print("error_rate:",float(rate) *100 /float(total),"%")
from sklearn import metrics
def metrics_result(actual,predict):
print("精度:{0:.3f}".format(metrics.precision_score(actual,predict,average='weighted')))
print("召回:{0:0.3f}".format(metrics.recall_score(actual,predict,average='weighted')))
print("f1-score:{0:.3f}".format(metrics.f1_score(actual,predict,average='weighted')))
metrics_result(test_set.label, predicted)
|