机器学习 - 逻辑回归实验
用scikit-learn和pandas学习Logistic回归
1. 获取数据,定义问题
泰坦尼克号的沉没是历史上最臭名昭著的沉船事件之一。1912年4月15日,在首次航行期间,泰坦尼克号撞上冰山后沉没,2224名乘客和机组人员中有1502人遇难。导致生命损失的原因之一是没有足够的救生艇给乘客和机组人员。虽然幸存下来的运气有一些因素,但一些人比其他人更有可能生存,比如妇女,儿童和上层阶级。
Titanic数据集分为两部分:
训练数据集-包含特征信息和存活与否的标签,train.csv
测试数据集-只包含特征信息,test.csv
数据集可以从kaggle上下载,格式为csv。
也可以在我的csdn资源里面下载:点击下载
我们要运用机器学习的工具来预测哪些乘客更可能幸免于难。
在这本次课的挑战中,我们要用逻辑回归算法,完成对哪些人更有可能生存的分析。
在scikit-learn中,Logistics回归通过linear_model.LogisticRegression类进行实现。
|
|
参考https://www.cnblogs.com/wjq-Law/p/9779657.html
|
|
2. 查看数据

Data columns (total 12 columns):
| PassengerId | 891 non-null int64 |
| Pclass | 891 non-null int64 |
| Name | 891 non-null object |
| Sex | 891 non-null object |
| Age | 714 non-null float64 |
| SibSp | 891 non-null int64 |
| Parch | 891 non-null int64 |
| Ticket | 891 non-null object |
| Fare | 891 non-null float64 |
| Cabin | 204 non-null object |
| Embarked | 889 non-null object |
可以看到,训练集一共包含891个样本,每个样本有12个特征,其中Age、Cabin和Embarked有缺失值。特别是Carbin特征,只有204个样本有值。
同理:观察测试集中的缺失值。
查看数据的其他函数:
|
|
3. 缺失值的处理
Age特征非常重要(逃命时通常女士和小孩优先),因此我们需要对其填充。
缺失值的填充方法有:固定值填充、均值/中位数填充、相邻值填充、模型预测填充。
此处我们使用均值填充。fillna()函数。

Cabin缺失值较多,我们直接将其舍弃,以免引入较大的噪声。(删某一特征,列) 用drop()函数。

Embarked特征在训练集中只有2个样本有缺失值,因此可以直接将有缺失的样本删除。(删某一样本,行)

同理,对测试集的缺失值进行处理。
4. 特征处理
现在的数据还存在一些问题,如Name特征是文本型,不利于后续处理,我们训练模型时暂时将其舍弃。Ticket特征比较乱,也将其暂时忽略。

Pclass特征、Sex特征、Embarked特征都是类别型,一般需要将其进行one-hot编码。

Age特征、SibSp特征、Parch特征和Fare特征为数值型,取值变化范围较大,一般先将其标准化或归一化。
标准化使用preprocessing.StandardScaler类库中的fit()函数和fit_transform()函数。
fit()用于计算训练数据的均值和方差, 后面就会用均值和方差来转换训练数据。
fit_transform()不仅计算训练数据的均值和方差,还会基于计算出来的均值和方差来转换训练数据,从而把数据转换成标准的正太分布。




5. 模型训练
(1)导入需要的分类算法类库。
|
|
逻辑回归函数的参数如下:
|
|
(2)将训练集中的特征值和标签分开提取。
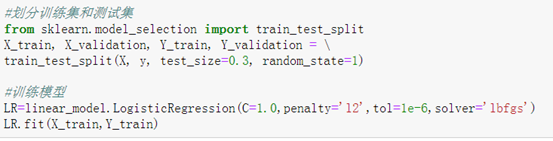
(3)划分训练集和验证集。
train_test_split()函数
(4)训练模型。
fit()函数。
(5)在验证集上验证,评估性能。





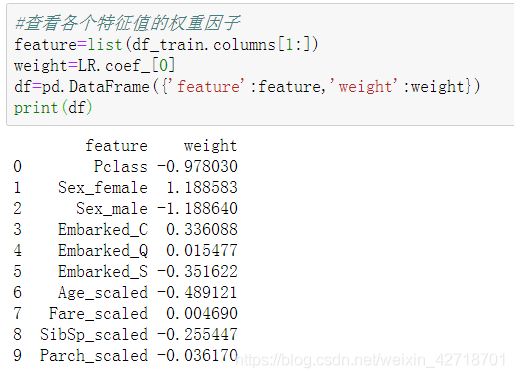
模型已经训练好,并且性能还不错,可以拿来进行预测了。
6. 完整python代码
|
|